CEF · signal reference · internal accuracy sheet
What the agent flags — recruiting vs coach
One engine, two verticals. This is the internal accuracy sheet behind the demo: every signal the agent actually computes, in plain language up top and in code underneath, with sources. It is not coach-facing material — the video is.
"Would a coach understand this?" The raw taxonomy below (0–1 scores, lens internals, file paths) is for the team, to confirm the demo is truthful. A coach sees the video, not this. But note: a relationship coach already speaks most of the coach column — Gottman's four horsemen, avoidant attachment, EFT pursue–withdraw are their own frameworks. That's the part to lead with. Fred's test: "why should people care?"
In plain language
The same signals, said the way the person you're selling to would say them, and why they'd care.
What it catches in an interview
- › Is this person reading a script or speaking from real experience?
- › Are they clear and specific, or hand-wavy and generic?
- › What did they dodge or talk around?
- › Were they actually engaged and curious, or flat?
- › How good was the interviewer — did they probe or let it slide?
- › Then it reconciles the résumé with how the call actually went.
What it catches in a conversation
- › Was your client (or their date) being real, or performing?
- › Where did they get defensive, avoidant, or shut down (the four horsemen)?
- › What they said vs what they meant — the moment between the lines.
- › How interested is the other person, really?
- › Should they follow up, and when — while it's still warm.
At a glance
Two agents in the marketplace, one shared engine underneath.
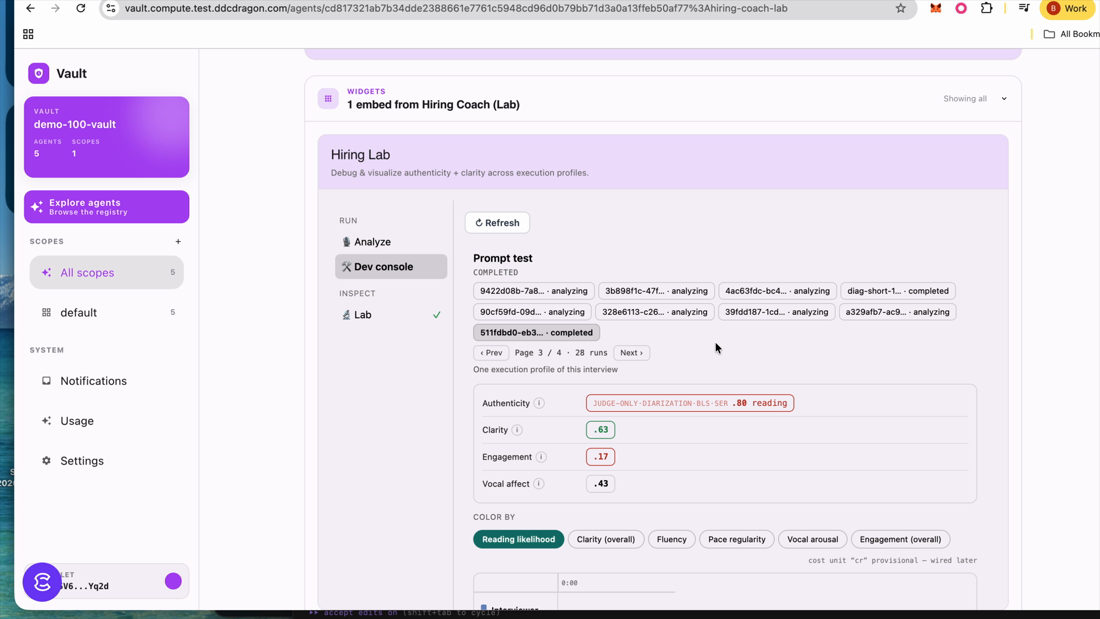
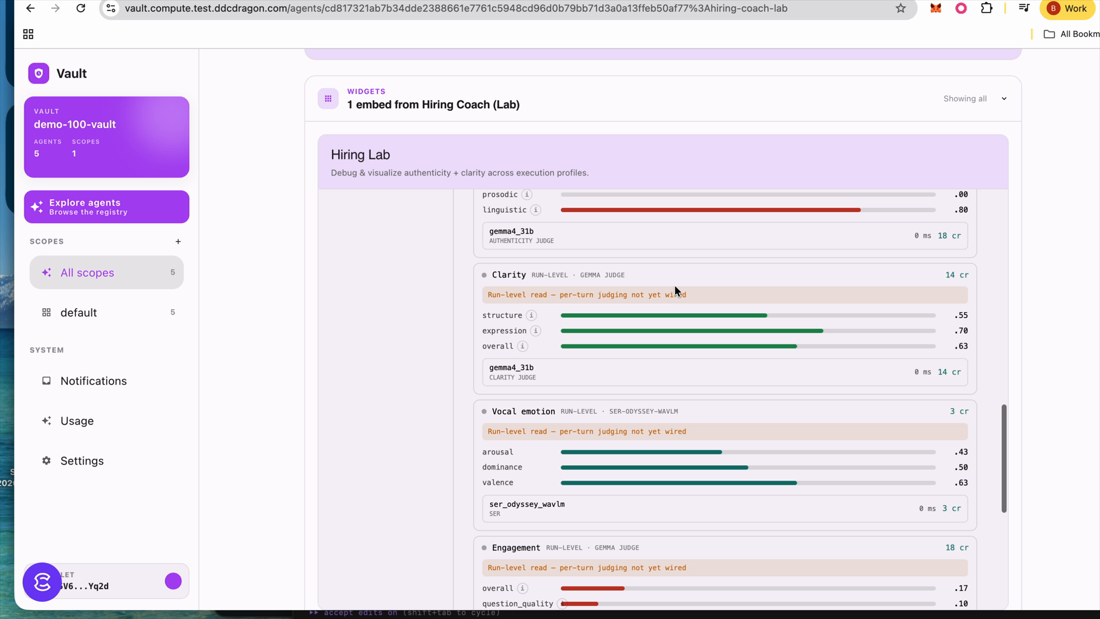
The shared engine — what relates to both
The genuinely cross-vertical layer. Same diarization + delivery/authenticity signals for an interview or a date. All scored 0–1 and explicitly advisory.
Source: CEF-AI/agent-catalog · packages/nlp-kit/src/diarization/extract-signal.ts:1-11 ("Lifted from dating-coach so every agent shares one diarization path… hiring → Candidate/Interviewer, dating-coach → user/partner"); delivery buckets agents/hiring-intelligence/src/delivery/metrics.ts:11-28; integrity/reading src/integrity/report.ts:11,51-62. Live values from Bren's Lab below.
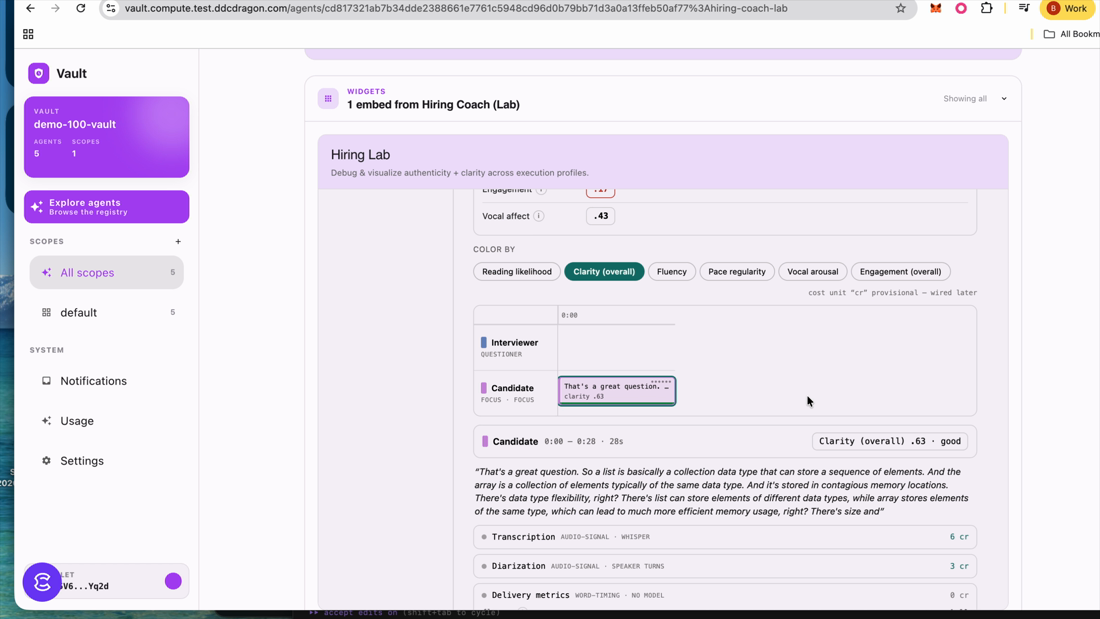
Recruiting signals — the interview lenses
On top of the shared engine, the hiring agent runs named "lenses" over the transcript. Each emits quote-grounded traits with a 0–1 confidence.
Source: CEF-AI/agent-catalog · agents/hiring-intelligence/src/lens/prompts.ts:4-35 (DEFAULT_LENSES); trait shape src/lens/schema.ts:6-13; semantic verdict src/lens/semantic.ts:9-18 (verdict ∈ strong·partial·missed, authenticity ∈ backed·unbacked·evasive·low_fluency, insight ∈ lived·recited·unclear, action ∈ proceed·reaffirm·walk_away). Per-fleet customizable: src/lens/store.ts:10 (lenses + prompt_overrides).
Coach signals — your own frameworks
The dating-coach reads "between the lines" (free-form) and tags moments against a science registry — the frameworks a relationship coach already uses.
| Framework | Tags it can apply |
|---|---|
| Gottman (four horsemen) | criticism · contempt · defensiveness · stonewalling |
| Attachment theory | secure · anxious · avoidant · disorganized |
| EFT | emotional_cycle · pursuer_withdrawer · reach_for_connection |
| NVC | observation · feeling · need · request |
| Vulnerability | vulnerability · authenticity · shame_response |
| Active listening | paraphrase · open_questions · reflective_summary |
| Cognitive distortions | mind_reading · catastrophizing · all_or_nothing · personalization |
Source: CEF-AI/agent-catalog · science registry packages/nlp-kit/src/science/registry.ts:10-60 (each framework has valid labels + a confidence floor); between-the-lines agents/dating-coach/src/analyze/schemas.ts:10-15 ({moment, they_said, they_meant, signal}); tag validation src/analyze/group-schemas.ts:13-29; verdict schemas.ts:4-8 (interest_score 0–10, should_follow_up ∈ yes·maybe·no); when-to-act schemas.ts:35-39 (send_within_hours); key moments ∈ missed_hook·good_catch·line_that_mattered schemas.ts:17-21.
Side by side
The full comparison. Shared rows are the engine; the rest is per-vertical.
| Dimension | Recruiting · Hiring Coach | Coach · Dale Coach |
|---|---|---|
| Subject | candidate interview recording | a date / client conversation |
| Delivery signals | SHARED · Authenticity (reading), Clarity, Engagement, Vocal emotion — all 0–1, advisory | |
| Content signals | lenses: evasion, confidence, bs, emphasis, subtext (+ 4 interviewer) | between-the-lines + framework tags (Gottman, attachment, EFT, NVC…) |
| Verdict | strong / partial / missed; action: proceed · reaffirm · walk_away | should_follow_up: yes / maybe / no |
| Score | résumé 0–10 → composite 0–10 (consolidation) | interest_score 0–10 |
| When to act | recommended_action | send_within_hours |
| Stage dimension | NONE in either. (No "interview round" / "relationship stage" matrix — the demo's old grid was invented.) | |
| Customization | per-fleet: pick lenses + rewrite any prompt | science-registry framework tags (global) |
| Graph nodes | Candidate, Role, Trait, Claim, BehaviorPattern, Outcome, Interview… | Date, Person, Topic, Claim, BehaviorPattern, CoachingFocus, User |
| Learning loop | lens weights ±0.05 (cap 6.0), outcome correlation/lift, human calibration | coaching-focus reinforcement; prior dates embedded as context |
| Shared layer | nlp-kit diarization + delivery engine (both); science registry (coach-only) | |
The score model
There is no 0–100 and no "92." The numeric output is 0–10, and the "revision" is a real consolidation step.
Source: CEF-AI/agent-catalog · résumé src/resume/schema.ts:5-11; consolidation src/analysis/consolidation.ts:14-46 + prompts.ts:4-24. Real fixtures: test/migrations/enums.test.ts:169 (prior_ai 7.5 / human 8.0 → composite 7.8); test/analysis/consolidation.test.ts (6 → 7). The demo's "7.5 → 6.8" is illustrative and labelled as such; the mechanism (a drop on a "contradicted/exposed" gap) is real.
Demo accuracy — what changed
Where the first demo drafted signals that did not match the code or the video, and what they are now.
| Element | Demo first claimed | Corrected to (real) |
|---|---|---|
| The read | 5×5 "signal matrix by interview round / relationship stage", 0–100 | delivery meters 0–1 + color-by + lenses/tags; no stage dimension exists |
| The catch | "92 confidence", "8.0 → 6.5 reject" | composite 0–10 (7.5 → 6.8 illustrative); verdict partial; reaffirm; advisory |
| Coach signals | defensiveness/commitment/escalation "by stage" | framework tags (Gottman/attachment/EFT) + between-the-lines + interest/follow-up/send-within-hours |
| Framing | "hire / reject verdict" | "advisory delivery signal, not a verdict or proof of misconduct" |
Sources
Everything above traces to one of these. Repos are private under the CEF-AI org.